ModernBert
Now this is Encoding

Back in my day, we didn’t have fancy GPTs -- we made do with humble BERT models (Bidirectional Encoder Representations from Transformers). It was a simpler time, playing
peek-a-boo with words in order to create predictions. Creating an AI God wasn’t on the agenda quite yet -- we were too busy determining who would
survive the Titanic
.
I am mostly being dramatic. Even though GPTs get the headlines, pure encoder models like BERT are still heavily used. In fact, they’re still state-of-the-art (as of June) for many language processing tasks.

Small models are ideal for compute-constrained tasks, which makes them perfect for my current hobby project -- redacting my personal info in-browser before sending it to STARGATE.
All the big GPTs are too compute-hungry to run locally in the browser, and all the small GPTs are a generation or two away from being useful. (I’ll write another article about that)
That leaves us with some version of BERT as our best option. Unfortunately, BERT is a bit peckish -- we can only feed it around 400 words at a time. That’s not much. I looked into various ways of chunking and concurrently processing that data within the browser -- it’s possible, but difficult to do without introducing significant latency and complexity.
Also, the existing models that are small enough to fit in a browser really struggle with identifying names, especially lower-cased ones.
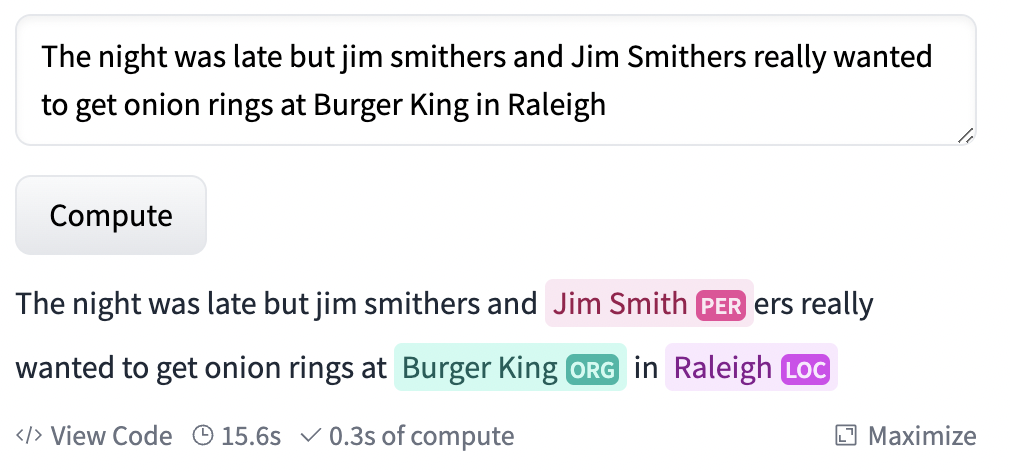 (see how the model only captures the lower-case name?) We can do better
(see how the model only captures the lower-case name?) We can do better
That’s why I was excited to see the recent announcement of ModernBert , a model that brings many of the recent developments in Transformer knowledge to BERT. These improvements allow for an input limit of 16x more tokens and 2-3x faster inference times. This sounded perfect for my use case.
Picking a Data Source
To be upfront, I’m not super knowledgeable about GPU programming or finetuning models. That will become apparent soon...
I was hoping someone had already trained ModernBert for Named Entity Recognition tasks (identifying, names, addresses, etc.) but I unfortunately couldn’t find anything published.
It appears there are two main datasets that people use for NER training: CoNLL 2003 and OntoNotes 5.0 (partially created by Raytheon of all people). OntoNotes is much larger and has more web-ish data, so I chose that one.
Misadventures in TPU World
For my cloud GPU provider, I chose Google Colab.
Colab offers standard Nvidia GPUs as well as TPUs (Google’s proprietary alternative to GPUs, which are specifically designed for AI tasks). I read up on both offerings and found that you can get a TPU with much more compute horsepower than a similarly priced Nvidia GPU. So I chose the TPU.
As ModernBERT is new, there are no tutorials showing how to train it for NER tasks. So, as a practice run, I followed a tutorial detailing how to train BERT - with intentions of swapping in ModernBert at the end.
I soon ran into problems though. I couldn’t get the pytorch tutorial code (which was designed to run on Nvidia) to run on the Google TPU. I kept getting terrible, cryptic error messages. I didn’t want to switch to Nvidia though, I was enlightened - TPUs are better, I’m a TPU man.
So, I switched from the PyTorch framework -> JAX (made by Google), which has much better TPU support. Unfortunately, compared to PyTorch, there’s very little documentation on how to do things in Jax. And since I’m not a very good GPU programmer yet, that’s worrying. I was lost in the wilderness for a bit, but eventually got the Bert fine-tuning working with Jax and the TPU. I was quite proud of my little model.
Now that I had fine-tuned with Bert, I thought I could just swap in ModernBert as the model. WRONG, I actually couldn’t do that. Turns out Jax and PyTorch model weights are not easily interchangeable (it can be done apparently, but not by me as a 1st project). And ModernBert hasn’t published Jax weights, so I had to throw away all my code and switch back to PyTorch :’(
It wasn’t that bad though - actually it was really fun. I rented an A100 and watched it go brrrrrrrrr
I later found out the A100 was definitely overkill, the much cheaper L4 works perfectly fine
Fiiiiine Tuning - Getting a Good Baesline
When I got my model up and running, the accuracy was much lower than I expected.
I kept troubleshooting my code, trying to find the bug.
Out of desperation I started searching the internet and found that other people were having the same problems.

Luckily, @stefan-it had identified the issue as stemming from the Tokenizer. Swapping in the ModernBert tokenizer for the ModernBert tokenizer fixed the issue.
Optimizing
The two biggest improvements came from drastically lowering both the learning rate and the batch size. According to the docs, ModernBert benefits from this more compared to other models.
I tried implementing some fancy techniques I read about (like Dice Loss), but I couldn’t really get it to move the needle. I’m sure they do work well, but I don’t know how to turn the keys .... yet.

I think there may still be some fundamental issues with how I’m tokenizing things (specifically regarding padding). That’s my guess on why techniques like adding a CRF didn’t improve the precision of my models -- the foundation is too shaky.
Results
This is for the ‘base’ version, not large. And on OntoNotes
Overall F1: 0.898
Person F1: 0.94723
Hopefully I’ve calculated correctly. I definitely haven’t gotten the full performance out of the model yet, but it’s high enough to be useful.
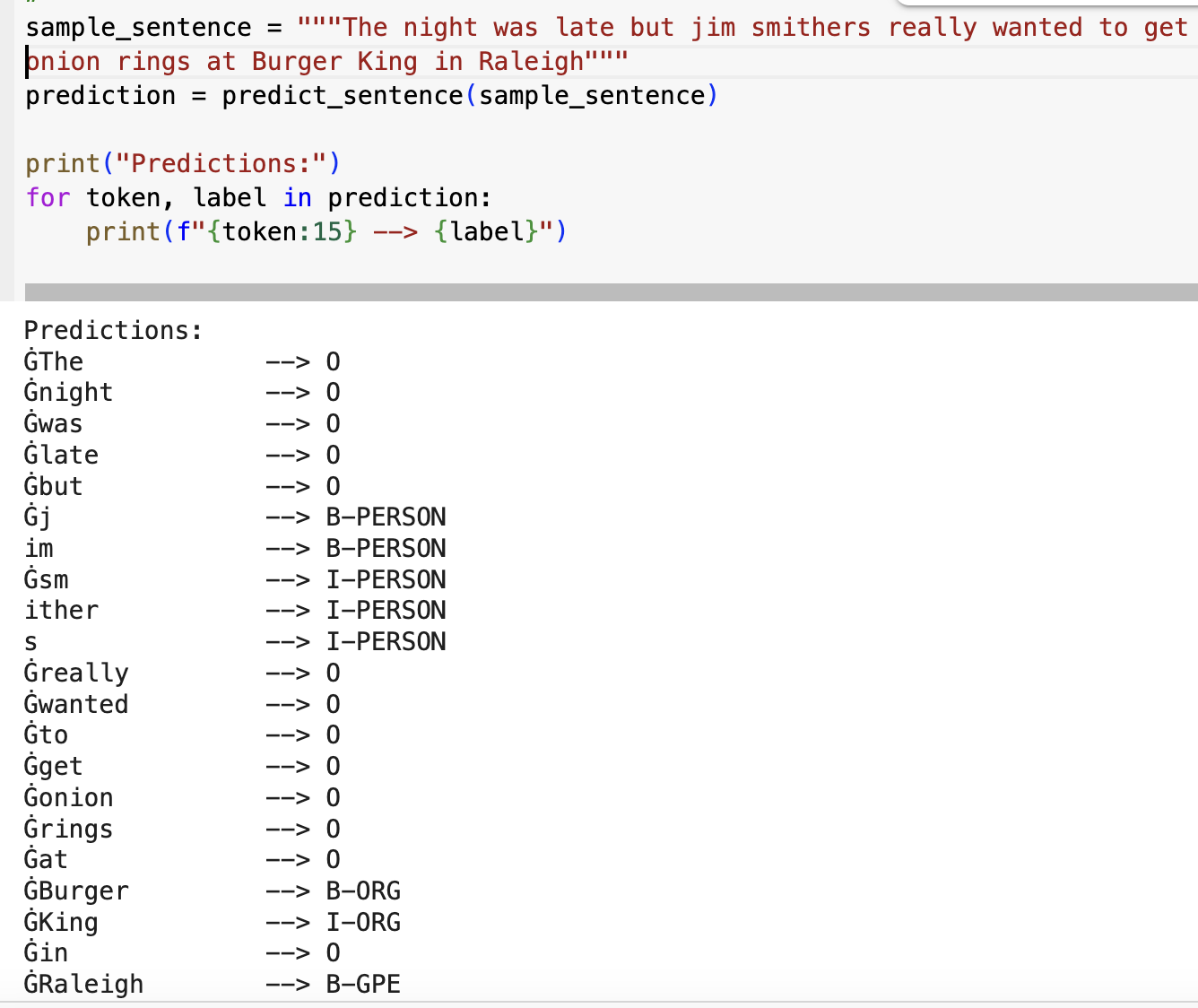
Remember how the model we previously looked at didn’t capture lowercase names? This model is pretty good at that
Things I’d like to do if I had unlimited time
-I'm deploying this model to the browser using Transformers.js. Currently, I'm just using the user's cpu, but I should be able to utilize the GPU to make inference much faster. Much of ModernBert’s speed comes from utilizing a gpu feature called ‘flash attention’. People mainly use this feature on Nvidia GPUs, but I think we can get it running on ‘metal’ (Apple’s graphics/compute API) so that Macs gets the speedup as well.
-Try fine-tuning the model with much longer datasets. I want to use this model on very long documents, but most NER datasets consist of paragraph-length or shorter documents. We might have poor model performance if there is a big descrepancy in train and inference size. We might need to create 8k token long synthetic documents if training docs of that size don't exist.
-Utilize the native Tokenizer (now that it’s been fixed)
-See how small I can make the webVersion of the model without totally lobotomizing it
-Fix the CRF I implemented. I think I’m doing something wrong because it only minimally improved my results. I want to try and implement it in a framework called Flair — someone already has started a version of this.
-Try to boost the Person metric by using data augmentation techniques. I tried a simplified version of this, but it made the model worse. I think a more sophisticated appraoch could yield improvements.
-Reduce randomness to create more reproducible results. I tried reducing randomness by seeding as many constants as possible, was only partially successful. Without sacrificing performance, some randomness seems unavoidable, but I believe I can reduce it. The statistical noise was making it difficult to determine whether my changes were having positive or negative effects.
-I'd also like to learn how to utilize tools like Tensorboard to get a better understanding of how to optimize models.
If you come up with a better fine-tune, let me know :)
Appendix
github:
https://github.com/mattlam/modern-ner/tree/main
HF:
https://huggingface.co/mlame/modernBERT-base-ontoNotes-NER
Tip: If you want to use Transformers.js, you can’t use the standard conversion script. Follow this solution by Wakaka6 or look for my modified script in my Github.
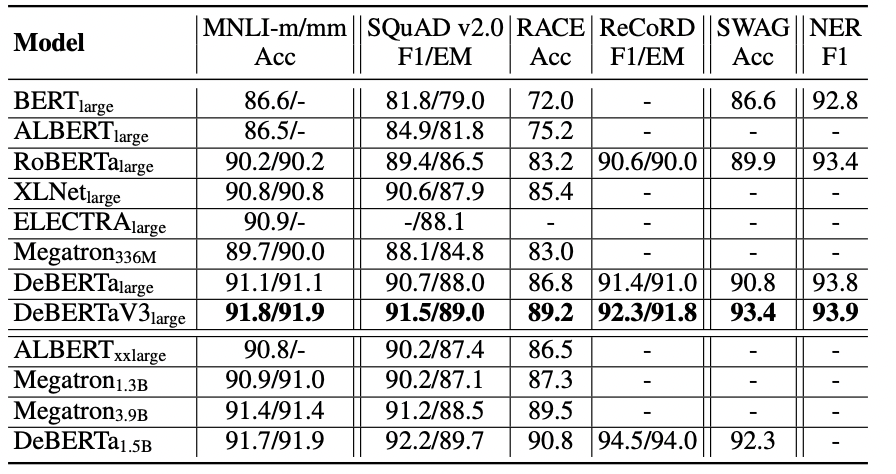
VS DeBERTav3
Very interesting post by Joe Stacey pointing out some reasons why DeBerta-v3 is still better at classification tasks than ModernBert. He points out that in the appendix of the ModernBert paper, they mention a limitation is that they only use Masked Language Modeling (MLM) as opposed to Replaced Token Detection (RTD).

I couldn’t find any benchmarks showing a big jump in NER performance from DeBerta V2 -> V3 (when they implemented RTD), but I’m going to trust them on this one.
Will be interesting to see if they add RTD in future versions of ModernBert.