Disclaimer: I don’t know much about Natural Language Processing, but that is the point of this article! This is my perspective as someone new to NLP, letting other beginners know it’s now fairly straightforward to get usable results.

Introduction
The Days of Yore (2015)
When I tried to use Natural Language Processing (NLP) for a project in 2015, there seemed to be two types of options:
1. Easy to Implement Solutions That Provided Low-Quality Results - These solutions were simple to get up and running, but only because the approaches were relatively unsophisticated. The results were low-quality, so it was difficult to do anything too interesting with these methods.
2. Trying to Copy Academic Papers - At the time, most info on state-of-the-art NLP work could only be found in academic journals. Because these papers didn’t include many implementation details, actually using these techniques was rather difficult. I remember painstakingly implementing a paper’s methodology, only to realize when I was finished that the method was unsuitable for my specific use case. To try a new method, I’d have to start from scratch on a different implementation - not fun! Also, everyone else working on similar implementations was absolutely brilliant, and possessed a deep knowledge of the field -- which was actually a downside for a beginner like me. When everyone discussing a topic has a PhD, there are ... not many questions on StackOverflow that are relevant to me haha
I ended up putting that project on the backburner and hadn’t looked at anything related to NLP since 2015. However, I recently started a new project where NLP would be useful, so I decided to check in and see how things had progressed.
What’s Changed Since 2015?
The biggest change I’ve noticed is that almost all of the top NLP models now have publicly available implementations. Most of the difficult work has already been done for us, and we just have to tweak things for our specific use case. Sweet!
I still ran into a few newbie roadblocks, so I’ll show how I recently went about implementing a NLP solution for a new project, in case it helps some other beginners.
Creating Shortened Summaries of News Articles
My project goal was to create a process that converts an entire financial news article into a three sentence summary.
There’s a neat site called PapersWithCode.com that lists all of the state-of-art approaches for different machine learning tasks.
For our goal of text summarization, there are a few different categories.
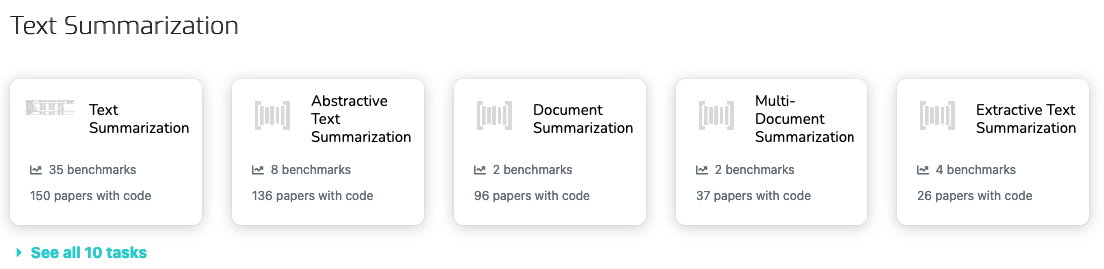
We’ll get deeper into the specifics later, but here are the definitions for the two main summarization techniques.
Extractive Summarization - “Given a document, selecting a subset of the words or sentences which best represents a summary of the document.” Source: PapersWithCode
Essentially, this method creates a summary by just copy/pasting the most important parts of the article.
Abstractive Summarization - “Is the technique of generating a summary of a text from its main ideas, not by copying verbatim most salient sentences from text.” Source: 2013 International Conference on Soft Computing and Pattern Recognition (SoCPaR)
Basically, in this method, the model creates summaries like a human would, by synthesizing the main ideas into brand new sentences. (not just copy/pasting)
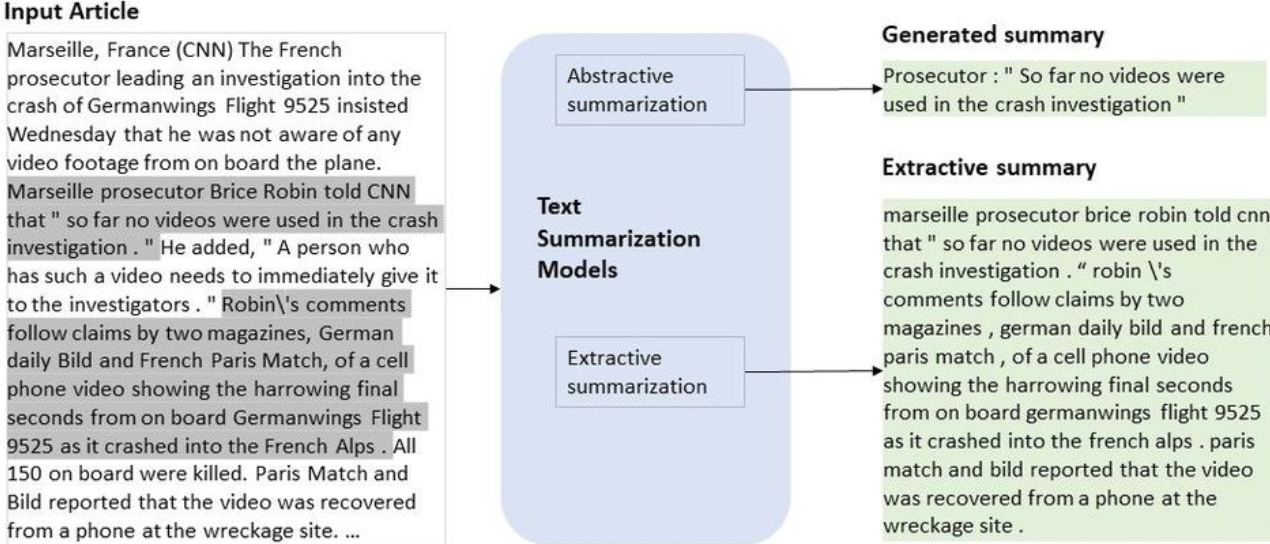
Source: Microsoft
Using that PapersWithCode website we looked at earlier, let’s check out which models are considered the best for creating abstractive summaries.
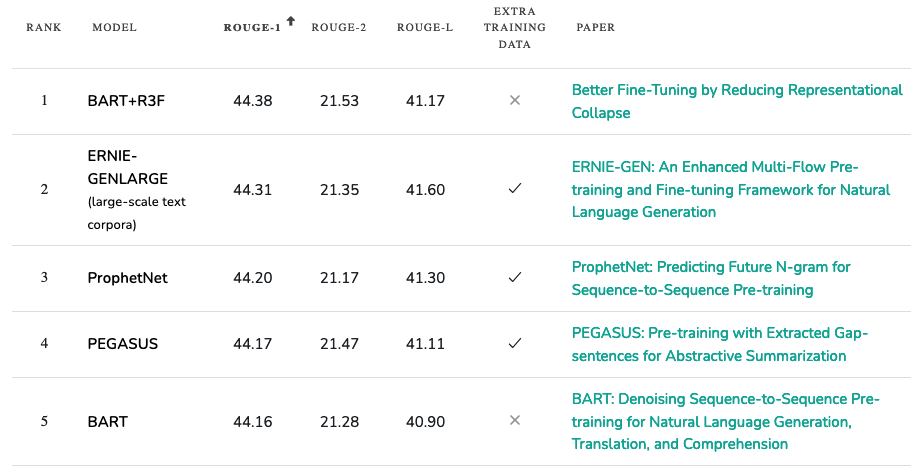
The models are ranked in order of their ROUGE scores, which is the industry standard for judging the accuracy of summarization models. ROUGE is a little complicated to get into here, but here is the original paper if you’re interested. ROUGE Paper
My ‘hot take’ is that ROUGE is actually a bad evaluation metric to use when judging Abstractive text summaries, and should not be the industry standard. In fact, optimizing for it may be counterproductive to producing good summaries! ROUGE rewards summaries which contain words that are identical to the words contained in the original document. However, we could produce an excellent summary which contains none of the words from the original document, right? This excellent summary would have a low ROUGE score, because although it has high ‘conceptual’ similarity to the original article, it has low ‘‘word’ similarity.
I did a Google Scholar search, and it seems that some academics are also concerned with this scoring system.
In the paper, Understanding the Extent to which Summarization Evaluation Metrics Measure the Information Quality of Summaries, Deutsch & Roth argue that “the summarization community has not yet found a reliable automatic metric that aligns with its research goal, to generate summaries with high-quality information.”
The main problem they identify is that the scores from ROUGE and BERTScore to compare summaries “largely cannot be interpreted as measuring information overlap, but rather the extent to which they discuss the same topics”. I agree! Link to Paper
There are a few different ROUGE alternatives that I’m testing, but we’ve probably already delved too far into the minutiae for this article. We need to just pick a model now.
I’ve heard good things about Pegasus, a text summarization model introduced by Google, so let’s try it out!
Actually Running The Models
The best website to use for quickly running models is HuggingFace. The name and logo kind of scare me, but it’s such an awesome platform.
The easiest way to get started is to use HuggingFace’s ‘pipeline’.
(Can run at this Colab I’ve set up: Link - Example #1)
!pip install transformers
from transformers import pipeline
summarization = pipeline("summarization")
original_text = """The Chrysler Building...""" #Goes on for 1000 words, but I’ve shortened here
summarizer = pipeline("summarization", model="google/pegasus-xsum", tokenizer="google/pegasus-xsum", framework="pt")
summarizer(original_text, min_length=50)
We’ll put the article we want to summarize in the “original_text” section. Then, we’ll use the model we want to use in the ‘tokenizer’ and ‘summarizer’ lines. ( google/pegasus-xsum )
If you want to use a different model, you need to find the naming format in the model section of HuggingFace’s website (pictures below).
Unfortunately, when we run this model with the original 1000 word article, we get an error that states “IndexError: index out of range in self”.
This took me a while to figure out, but there are limits to how long the original text can be, based on how the model was trained.
See below for the actual limits for the model we’re using, Pegasus X-Sum.

Because we’re using the x-sum model, the text we input needs to be a maximum of 512 “tokens”. We can theoretically increase this token limit, but it would require a significant amount of work. We would need to either re-train the model to use a different token length, or use a different transformer. Big Bird Paper Link For simplicity, we’re not going to do either here, we’ll just shorten our input text to 512 tokens.
What is Tokenization?
Tokenization is how we divide text strings into smaller units (tokens) for processing, so it can be more easily interpreted by the model. Usually, 1 word equals 1 token, but there are quite a few exceptions. For example, “Matt’s” will be broken into three tokens (“Matt”, “‘“, and, “s”). This helps the model recognize things like possession.
(Can run at this Colab I’ve set up: Link - Example #2)
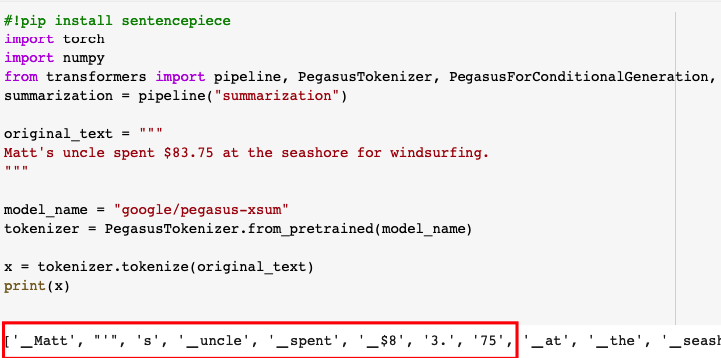
(the words in red are considered ‘tokens’)
Now that we’ve shortened our text to be within the token limit, our model should actually return an output. Let’s see how it works.
Original Text: The Chrysler Building, the famous art deco New York skyscraper, will be sold for a small fraction of its previous sales price.The deal, first reported by The Real Deal, was for $150 million, according to a source familiar with the deal. Mubadala, an Abu Dhabi investment fund, purchased 90% of the building for $800 million in 2008. Real estate firm Tishman Speyer had owned the other 10%.The buyer is RFR Holding, a New York real estate company. Officials with Tishman and RFR did not immediately respond to a request for comments.It's unclear when the deal will close.
Summarized Text: One of New York City's most famous buildings has been sold to a New York real estate company, according to a report from the Wall Street Journal. The Chrysler Building, the famous art deco New York skyscraper, will be sold for a small fraction of its previous sales price
My Evaluation: This ‘abstractive’ technique is pretty interesting, because it is formulating brand new sentences that seem like they were written by humans. The downside is that the model sometimes goes off the rails. In the summarized version, it says the event was first reported by ‘the Wall Street Journal’. Where did it pull that from? That was not in the original text.
With Abstract summarizations, it seems the inclusion of incorrect information is fairly common. In the paper FEQA: A Question Answering Evaluation Framework for Faithfulness Assessment in Abstractive Summarization , the authors found “that current models exhibit a trade-off between abstractiveness and faithfulness: outputs with less word overlap with the source document are more likely to be unfaithful.” That is unfortunate :( Link to Paper
For some use cases, a highly abstractive technique might work, but I would be worried about using it for financial applications, where the specific details are critical.
Financial-Summarization-Pegasus Model
What if the model was specifically trained on financial articles - would we get better results? Luckily, someone has already done this, so we can use their model. (shoutout Passali, Gidiotis, Chatzikyriakidis and Tsoumakas) Model Link
(Can run at this Colab I’ve set up: Link - Example #3)
Original Text: The Chrysler Building, the famous art deco New York skyscraper, will be sold for a small fraction of its previous sales price. The deal, first reported by The Real Deal, was for $150 million, according to a source familiar with the deal.Mubadala, an Abu Dhabi investment fund, purchased 90% of the building for $800 million in 2008.Real estate firm Tishman Speyer had owned the other 10%.The buyer is RFR Holding, a New York real estate company.Officials with Tishman and RFR did not immediately respond to a request for comments.It's unclear when the deal will close.The building sold fairly quickly after being publicly placed on the market only two months ago.The sale was handled by CBRE Group.The incentive to sell the building at such a huge loss was due to the soaring rent the owners pay to Cooper Union, a New York college, for the land under the building.The rent is rising from $7.75 million last year to $32.5 million this year to $41 million in 2028.
Summarized Text: The Deal, first reported by The Real Deal, was for $150 million. The building had been on the market for only two months
My Evaluation: For our use case, this summary is better than the generic Pegasus model. It didn’t get any information incorrect, and it included the sale price, which is important. However, it did have a weird capitalization of ‘Deal’ -- maybe because deal was capitalized in the original text? It also left out other key details of the sale.
BART Model
The BART model is the most used text summarization model on HuggingFace. Do the results match up to the hype? Let’s see.
(Can run at this Colab I’ve set up: Link - Example #4)
!pip install transformers
from transformers import pipeline
summarization = pipeline("summarization")
original_text = """Chrysler...""" #Full text in linked document
summarizer = pipeline("summarization", model="sshleifer/distilbart-cnn-12-6", tokenizer="sshleifer/distilbart-cnn-12-6", framework="pt")
summarizer(original_text, min_length=50)
Original Text: Same as in the previous examples.
Summarized Text: The Chrysler Building, the famous art deco New York skyscraper, will be sold for a small fraction of its previous sales price . The deal was for $150 million, according to a source familiar with the deal . The incentive to sell the building at such a huge loss was due to the soaring rent the owners pay to Cooper Union, a New York college, for the land under the building.
My Evaluation: This method produced a very high quality summary. It’s a little less ‘cool’ than the other methods, because it’s not formulating any ‘new’ sentences, just copy/pasting the most important ones. This is probably the model I would use, especially for use cases where it is critical to have accurate details.
Conclusion
It’s fairly straightforward to get some interesting results using NLP, even for people like me that don’t really know what they’re doing. I encourage other beginners to try it out!
To improve the above results, we could ‘fine-tune’ the models by training them on an additional dataset that is specific to the task we are performing. Maybe we’ll cover how to do that in the next post?
Also, if anyone can point me towards interesting articles/approaches for evaluating Abstractive text summaries, please let me know! If not, I’m going to develop my own crank theories, and no one wants that haha
Email : Lamers@outlook.com